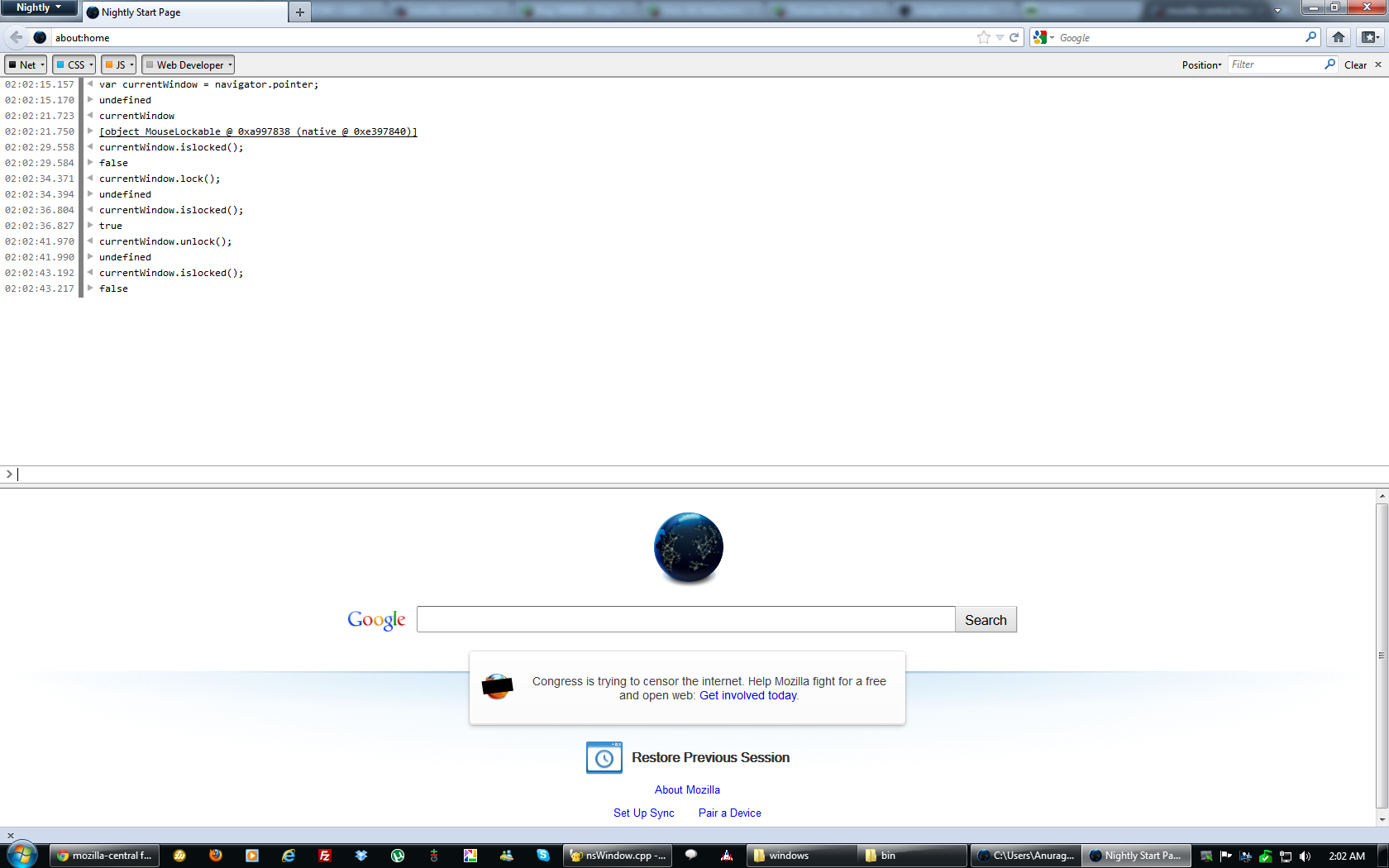
This was the third year I attended Free Software and Open Source Symposium, having volunteered at the event back in my first year (2008). As usual I expected a large number of speakers from Mozilla and Seneca to come, and was pleasantly surprised to see an even bigger turn-out, like Red Hat which I believe was a first. (2011 Speakers).
I want to discuss my impressions from two of the presentations I attended.
Building a Commercial Game Using Processing.js for Cross-platform Delivery by Daniel Hodgin and David Perit
Being familiar with Processing.js and now even hacking pjs as part of my open source project, I was curious to attend this presentation. I was already well-aware of several advantages developing a game in pjs might have, given that it runs on a browser, which makes cross-platform delivery easier, but the presentation left me with a better understanding overall.
The presentation was introduced by Dawn Mercer who is championing the project at FSOSS, and then by the founder and CEO of SpongeLabs, Jeremy Friedberg. Jeremy introduced his company and the objectives of this collaboration with FSOSS. His goal was to develop an educational game that could reach a large number of students easily. Specifically, his interest was in developing a game that was able to better impart the lessons of Mendelian genetics to students in high school. He said he had come to a realization that the era of installed software was gone, and to reach his target audience of students in schools, he would have to find another way of delivery, one that could circumvent downloading and installing new software, as most school computers don’t have admin rights. He also wanted to find a solution that relied on as little of external plug-ins as possible, for the same reason.
In collaborating with CDOT, he found the solution in processing.js.
From here the lead developer of the project – Daniel Hodgin took over and went over a brief overview of additional advantages that processing.js (pjs) had to offer for such a project. It was apparent that as an open technology, having no licensing fees was a big factor in their decision to select pjs. Also the fact that a large part of development of pjs was done right here at CDOT, it made it easier for the developers to be able to reach the developers of pjs as they needed some assistance. Daniel actually mentioned an instance when he came across a bug in pjs, and he took it up with John Buckley at CDOT, and was able to get it resolved within a matter of hours. In such cases an open technology offers great advantage as opposed to one where the support might not be as readily available or the documentation might not be as thorough, and that requires additional plug-ins to run. Ofcourse, one of the main benefits of pjs was that it can run on a browser and had practically no compile time, and from the perspective of SpongeLabs who want to get the game out there to the students, it is a perfect way to do so.
The presenters had a positive outlook of open source technologies, evident not just in the fact they were using pjs in their project, but the advantages they listed and the fact they worked at CDOT. The CEO of SpongeLab who was sponsoring the project shared the enthusiasm of the developers in using an open source technology in this case, as pjs was able to meet all of the minimum requirements they had from it.
Take control of your TV with XBMC by Lawrence Mandel
The second talk that I attended was by an employee of Mozilla – Lawrence Mandel – who was a fan of xbmc and so decided to spread the word about it at FSOSS.
XBMC was started as the X-box Media Centre project in 2004. It is licensed under GPL-2 and is thus an open source project. The project developed its own governing body by 2005 and its developer base around the world started growing rapidly. It outgrew as a media centre just for the xbox and can now be run on any device such as a game console or Apple/Google TV after jail-breaking.
The main objective of XBMC is to be able to control your tv and the content on it. XBMC’s interface allows you to access all your digital media – photos, videos, music from a hard-drive and easily sort through it. It runs on all platforms – Windows, mac, linux and ios. In some technical specifications it performs better than Apple tv, such as the video quality. While Apple TV cannot play media higher than 720p, xbmc allows the user to watch even in 1080p. The user-interface of the media centre is one of its main features that make it quick and easy to navigate through a large media library, finding favorite items easily, or the next episode in a tv series etc. Being an open source project, its interface and functionality is highly customizable. Several vendors and third party developers have developed their own add-ons to the platform, for selected content or to add functionality. For example, several add-ons exist that allow you to live stream sports content on your tv, or news, or even Netflix and Youtube.
The presented mentioned there were a few other open source projects doing the same thing, but didn’t go into any detail comparing them. He demoed how xbmc can be used to control content via a network – by connecting all the TVs in a home and then controlling them from an android phone or a tablet.
The speakers of both the talks displayed a great deal of enthusiasm for the open source projects that were behind the products that they were using – pjs and xbmc. The presenters in both the cases were not directly involved in the development community, yet could appreciate how the open source model was able to create a good quality product. Both the speakers made a point to compare the benefits of the project being open source as opposed to a commercial project, in terms of less restrictive licensing terms.
This year’s FSOSS was a newer experience for me as it is my first conference since I am actively taking part in an open source project. There are some points that came to my mind as I attended the talks this year:
As the lead developer in the first talk demoed the headway they were able to make in their project in just 4 months, I couldn’t help but think the tremendous advantage they had in using a language as pjs. In addition to the points mentioned by the speaker, I realized how beneficial their project was to the pjs community as well. While a large developer community assured the longevity of pjs, projects such as the genetics game also bring more attention to the pjs project. It is a symbiosis relationship where the developers using pjs are assured by the fact that the project won’t get abandoned anytime soon, while the open source community finds a client who can test their product, find more bugs and give the project some direction.
I am sure the application of pjs in game development will influence the functionality that is developed into the project. As the popularity of pjs for game development grows, it will inevitably push the open source project into developing more functionality in 3D, better rendering, more audio and keyboard controls. As the requirements of game developers grows – for example, faster loading of images and better caching of images for animations – the better influence it will have on the development of pjs. One more huge benefit of using an open source technology is that when a third party developers finds some functionality is lacking in pjs or any other project, they can add it themselves, and even contribute it back to the community as a plug-in.
This collaboration between developers who use the product and the open source community also helps improve the efficiency of the code as more of it is re-used, the documentation of the code improves and so does the functionality.
One of the big features of open source projects is of course their licensing terms. This also plays a big role in encouraging others to adopt the technology and develop it further and contribute something back to the project. In the xbmc talk, the presenter discussed one of the main advantages that xbmc had over Apple TV was that the content did not have to be DRM protected, unlike Apple TV, where all content had to be managed through iTunes – a black box for users. The open source alternative to Apple TV allows users to customize the look, the functionality, extend the functionality and use it however the users wants to use it without the restrictive terms most commercial software have.
I have been a big user of WordPress and jQuery over the past 3 years and I have developed some plug-ins myself and customized others. I can see how the users that use these projects influence their future development. It allows developers to stand on each other’s shoulders and produce something that, because of its open nature, offers a great deal more advantages than another similar commercial project.
These features are also evident in several other large open source projects that have attracted large developer communities around them – Android, Mozilla, Arduino and of course Linux.
Update: Link to Building a Commercial Game Using Processing.js for Cross-platform Delivery presentation
November 4th, 2011 at 6:04 PM